
Hello and welcome to our exploration of integrating AI into the world of Magic: The Gathering (MTG). This project, a humble attempt at creating an MTG Assistant using OpenAI's Assistant API, is more of a personal endeavor than a groundbreaking innovation. It's about combining a hobby I love with the intriguing world of artificial intelligence.
MTG is a game known for its complexity and depth, where building the right deck is both an art and a science. The MTG Assistant is our modest attempt to bring a bit of AI assistance into this process. It's not an expert system, but more of a learning project where we've experimented with AI's potential to aid in deck building and card selection.
In this blog post, we'll take you through the inner workings of this project. We'll discuss how the backend manages the assistant's interactions, the decisions behind the frontend development, and the integration of the MTG API for card data retrieval.
This project is very much a work in progress, and there's plenty of room for improvement. Whether you're an AI hobbyist, an MTG player, or just someone curious about the application of AI in gaming, I hope you find this exploration interesting. Let's delve into this journey of mixing technology with the magic of a beloved card game.
Features
Knowledge Retrieval through Embeddings:
At the heart of the API's prowess is its ability to understand and retrieve information. It's not just about matching keywords but understanding concepts. When you ask the MTG Assistant for card suggestions, it's using embeddings—think of them as multidimensional context vectors—to pluck out the most relevant bits from a sea of MTG rules and card databases.
Contextual Coherence in Conversations:
At the heart of the API's prowess is its ability to understand and retrieve information. It's not just about matching keywords but understanding concepts. When you ask the MTG Assistant for card suggestions, it's using embeddings—think of them as multidimensional context vectors—to pluck out the most relevant bits from a sea of MTG rules and card databases.
Dynamic Responses and Recommendations:

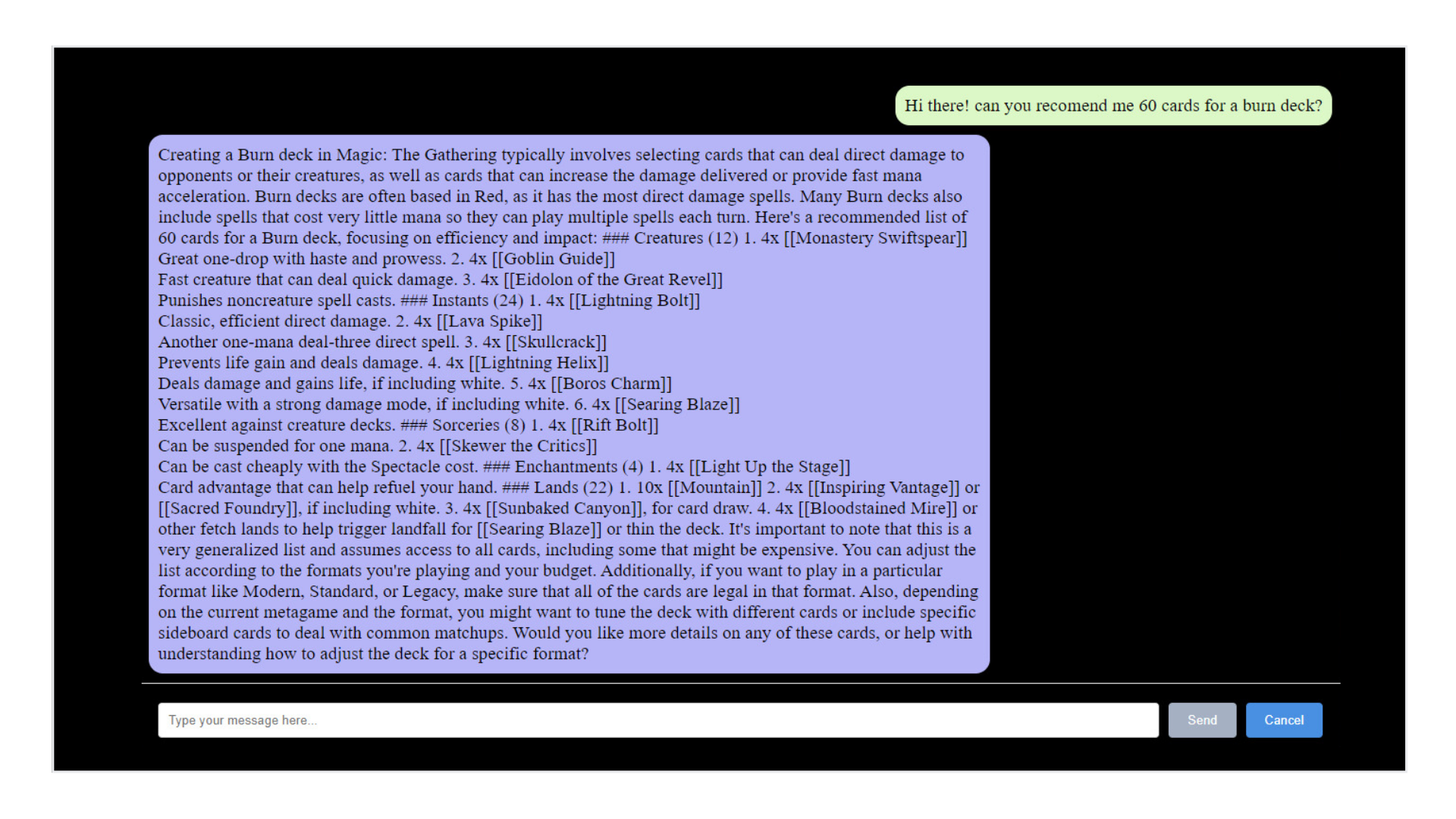
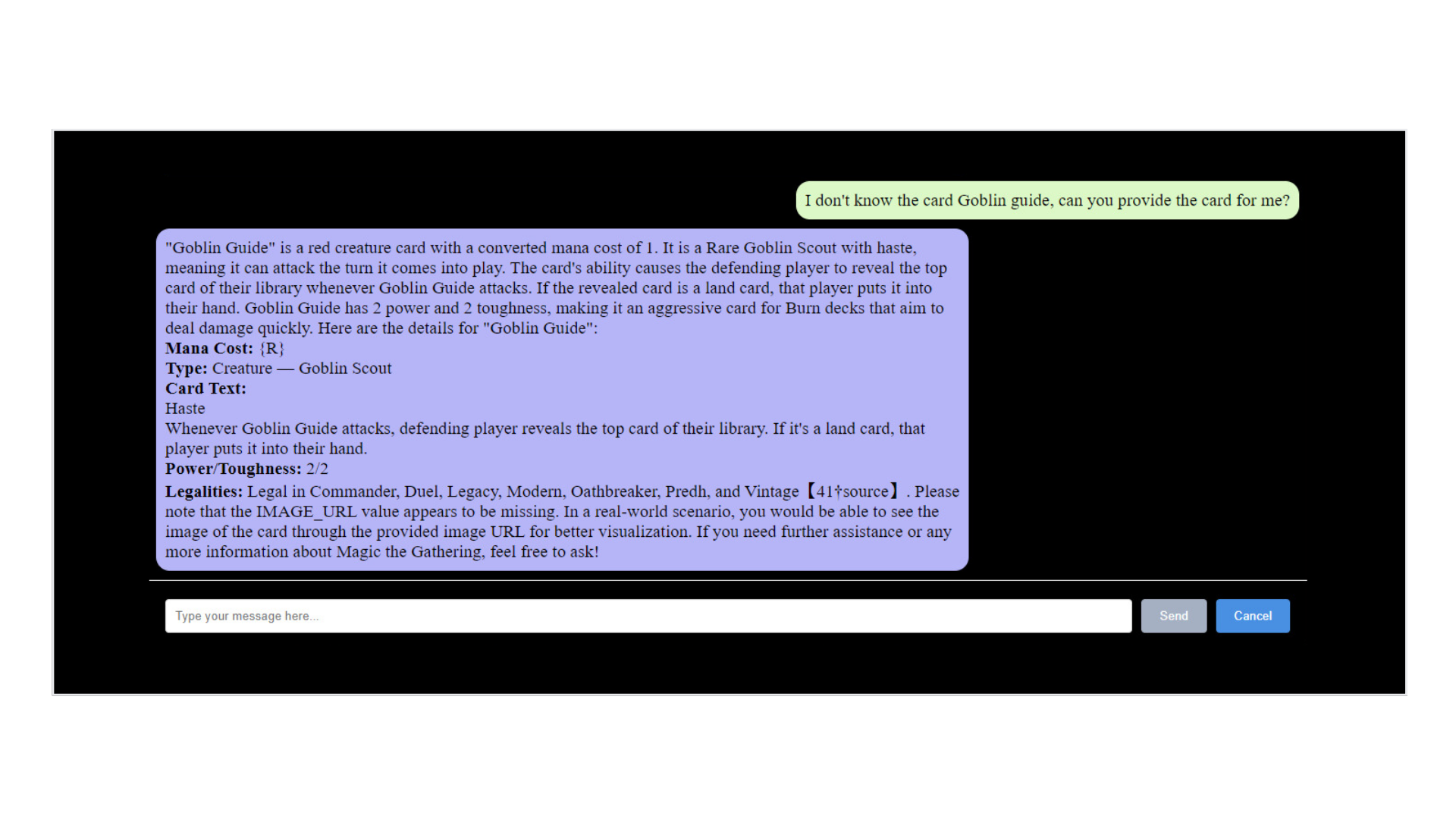
Want to know what can replace your worn-out 'Goblin Guide' in a burn deck? The API dynamically generates recommendations based on your current deck's strategy and the cards you already own. It's not just spitting out a static list; it's tailoring its suggestions to fit your play style.
Keeping Track of Chat History:
Much like a good player remembers the moves that have been made, the Assistant API keeps track of the conversation. This ensures that each interaction builds on the last, making for a cumulative and personalized experience.
Using external APIs
The true versatility of the OpenAI Assistant API shines when it can reach beyond its internal capabilities and tap into external data sources. By running arbitrary functions, the Assistant can interact with third-party APIs to fetch specific data—in this case, card information from the MTG API.
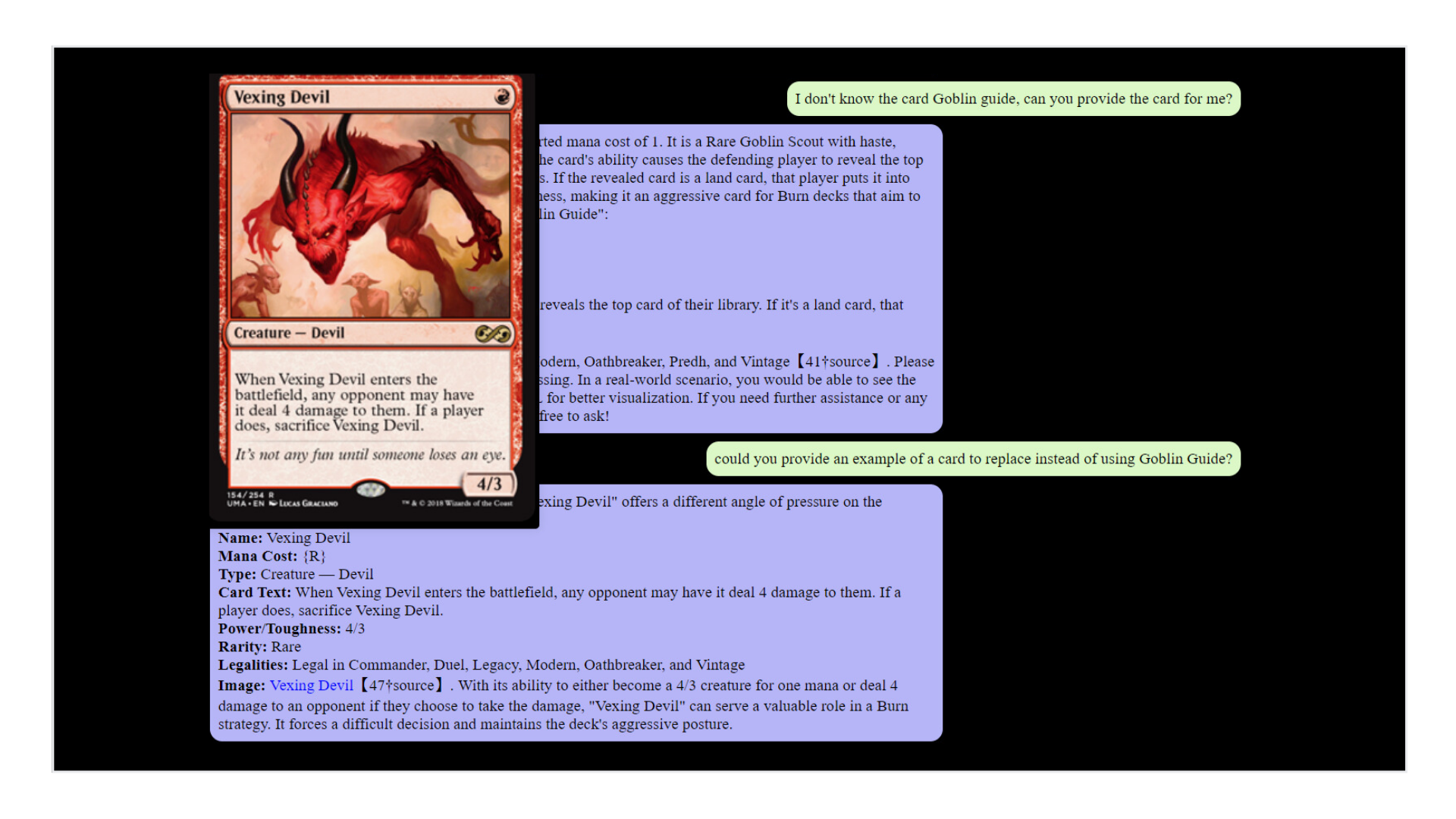
Imagine you're looking for a replacement for the 'Goblin Guide' in your deck. The Assistant, through its integration with the MTG API, can query a vast database of cards and bring back options. It's not just searching for a name or a type; it's considering the synergy with your existing deck, the current meta of the game, and your personal play style.
Now, why does all this matter? For developers and MTG aficionados looking to build their own digital assistants, the OpenAI Assistant API offers a toolkit for creating sophisticated, context-aware applications. Whether you're designing an app to help players build decks or just looking to automate some aspect of gameplay, the API provides a robust foundation.
In the next sections, we'll get our hands dirty with some code snippets that bring the MTG Assistant to life. You'll see how these API features translate into real-world interactions and, hopefully, get inspired to create something unique yourself.
How does the Assistant API work?
The Assistant API is OpenAI's toolkit for creating conversational AI models that can perform a myriad of tasks. Let's unpack the components and processes that enable this API to power applications like an MTG assistant.
Threads and Messages:
The conversation between an AI and a user occurs within a 'Thread', a digital space where messages are exchanged. These messages can be user queries or AI responses, including text, images, and other files. As the conversation evolves, the thread dynamically manages the context to ensure the AI understands the subject's history. However, it smartly truncates older parts when the dialogue exceeds the model's memory limits.
Persistent Objects:
To enrich interactions, the Assistant can reference 'Files' — these could be datasets, images, or documents. For instance, to help with MTG, the Assistant could refer to an uploaded database of card information.
Runs and Run Steps:
When the AI is invoked to process a user's input within a thread, that's a 'Run'. Each Run is a record of the AI's task, which can include processing the latest message, retrieving information, or executing code. 'Run Steps' provides a detailed account of each action the AI takes during a run, offering transparency into the AI's thought process.
Assistant Customization:
Developers can tailor the Assistant's capabilities and personality. By setting 'instructions', you define the Assistant's tone and scope of knowledge. Moreover, you can equip the Assistant with up to 128 'tools', like a code interpreter for running Python scripts or a knowledge retrieval function to cite information from uploaded files.
Creating Assistants:
Building an Assistant is as straightforward as specifying a model. Yet, the real magic happens when you personalize it. You could instruct your MTG Assistant to focus on creating visual data analyses from .csv files, making it a specialized tool for players who love statistics and probabilities.
File Management:
Files are central to the Assistant's intelligence, allowing it to access additional information as needed. Files can be associated with an Assistant or a Message and can be created or referenced by the Assistant during a Run.
Managing Context:
The API automates context management, keeping the conversation coherent without manual intervention. This means the Assistant remembers the relevant parts of a conversation, so users don't have to repeat themselves.
Annotations:
To enhance clarity, the Assistant can annotate its messages. For instance, when citing information from a file, it can include a reference that developers can program to display as a citation in the conversation.
Run Lifecycle:
Runs can have various statuses like 'queued', 'in_progress', and 'completed', allowing developers to track the AI's work and manage user expectations. Plus, developers can 'poll' for Run updates, which means checking regularly to see if the AI has completed its tasks.
For more info, you can visit Open Ai’s Assistant API docs directly via this link: Docs.
Let’s dive deep into the actual code
Tech stack:
- Next.js
- Typescript
- OpenAi Node Library
- MTG SDK wrapper for Node.
Backend:
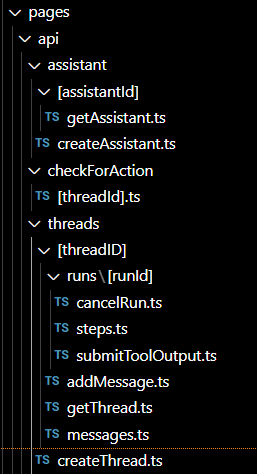
Let’s start by taking a look at the endpoints that our backend has.
getAssistant.ts:
This endpoint retrieves details about a specific assistant using the AssistantService. It handles GET requests, expecting an assistantId in the query parameters. If the required assistantId is present, it fetches the assistant details; otherwise, it returns an error.
createAssistant.ts:
This endpoint is responsible for creating a new assistant instance. It processes POST requests, takes necessary details like name, description, model, and additionalTools from the request body, and uses the AssistantService to create the assistant.
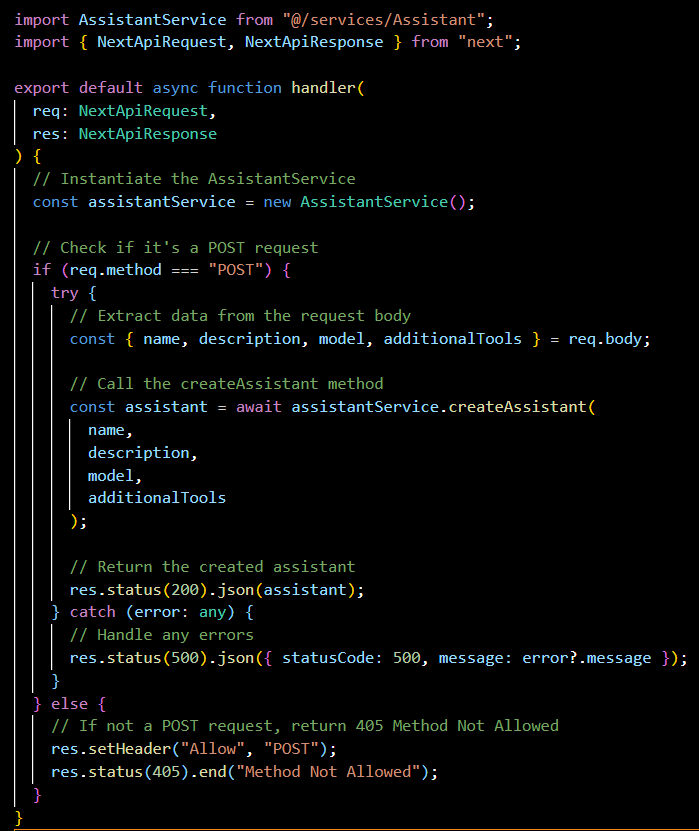
check-for-action/[threadId].ts:
The purpose of this GET endpoint is to check for any required action on a thread specified by threadId. It uses the AssistantService to determine if there's any action the backend needs to supply by running a function, for more info on function calls with assistants you can refer to: Tools Docs.
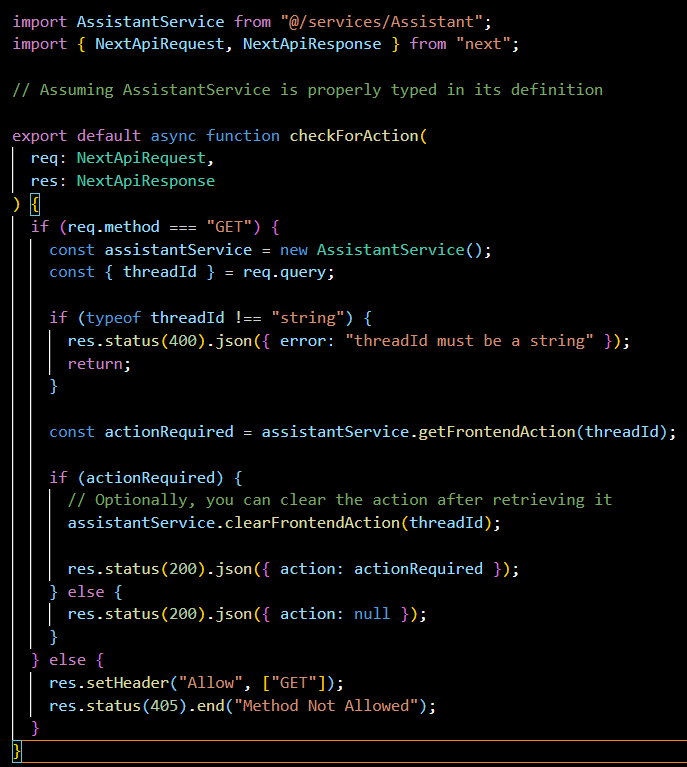
threads/[threadID]/runs/[runId]/cancelRun.ts:
This POST endpoint allows the cancellation of a specific run within a thread. It uses the threadId and runId from the query parameters to identify which run to cancel through the AssistantService.
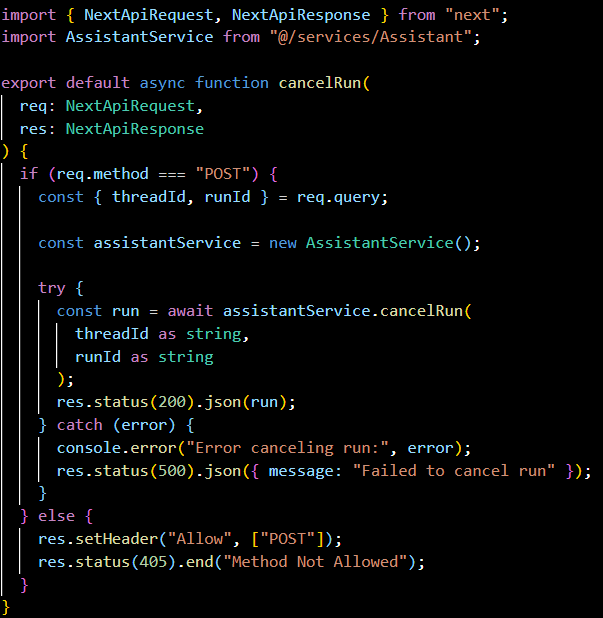
threads/[threadId]/runs/[runId]/steps.ts:
A GET endpoint that lists the steps taken during a specific run. It is intended to provide transparency into the actions performed by the assistant during the run.
threads/[threadId]/runs/[runId]/submitToolOutput.ts:
This POST endpoint is for submitting the outputs of various tools that the assistant might have used during a run. It captures the toolOutputs from the request body and associates them with the specified threadId and runId.
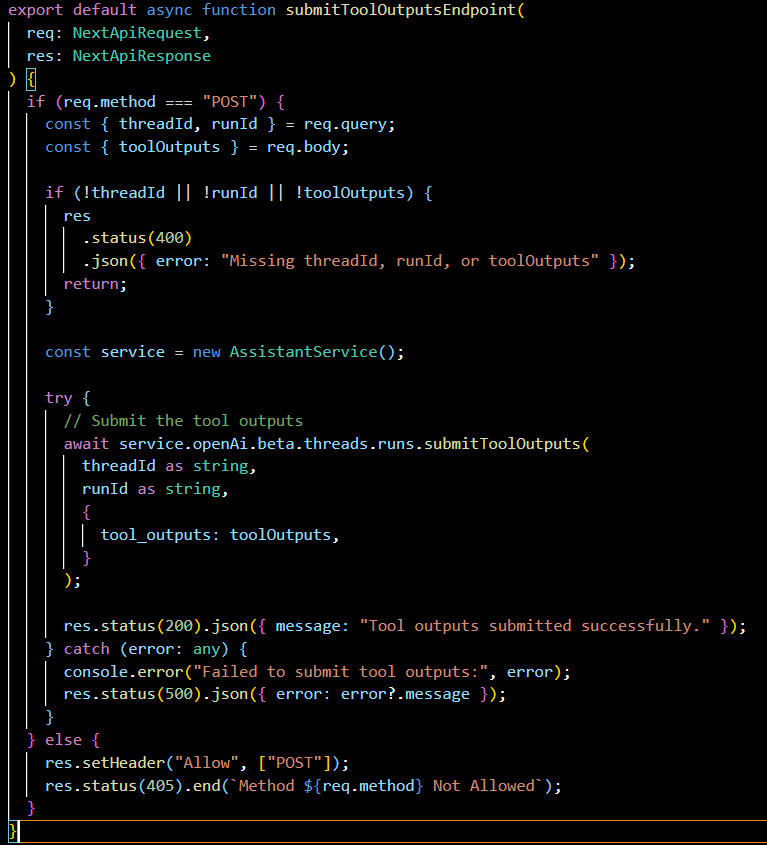
threads/[threadId]/add-message:
A POST endpoint that handles adding a new message to a thread. It also initiates a run using the assistant and manages the lifecycle of that run, ultimately responding with the updated messages in the thread.
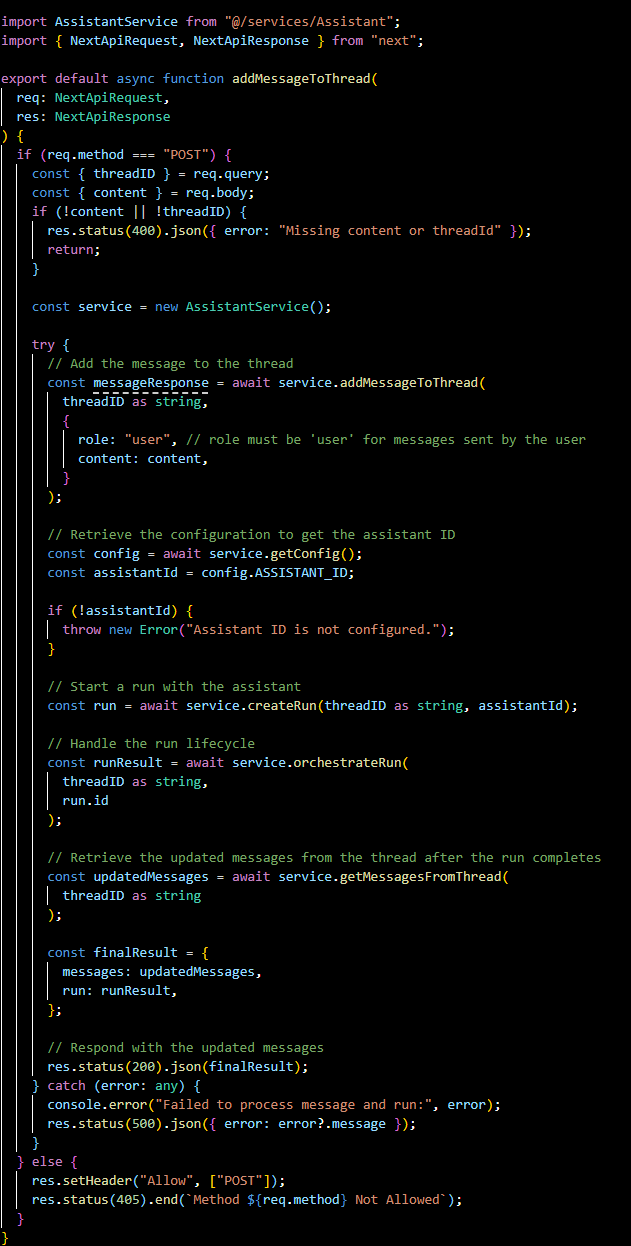
[threadID]/getThread.ts:
A GET endpoint that fetches all the details of a specific thread using the AssistantService. It requires a threadId to identify which thread's details to retrieve.
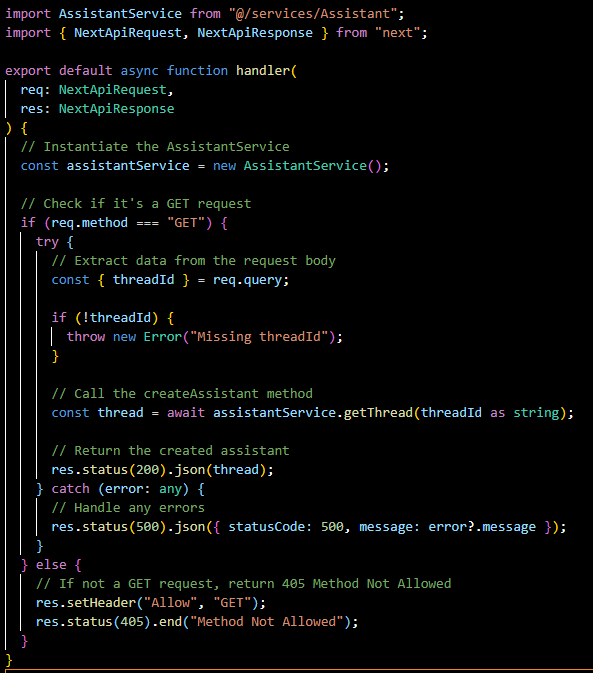
threads/[threadId]/messages.js:
This GET endpoint retrieves all messages from a specified thread. It ensures that all communication within a thread can be accessed, providing a history of the interaction between the user and the assistant.
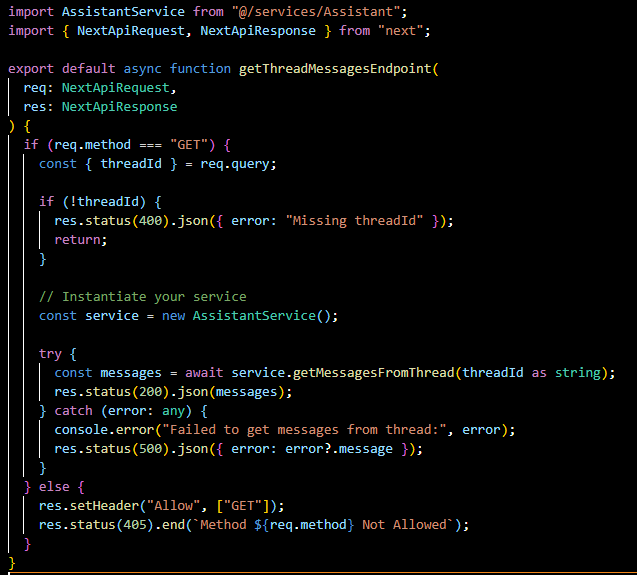
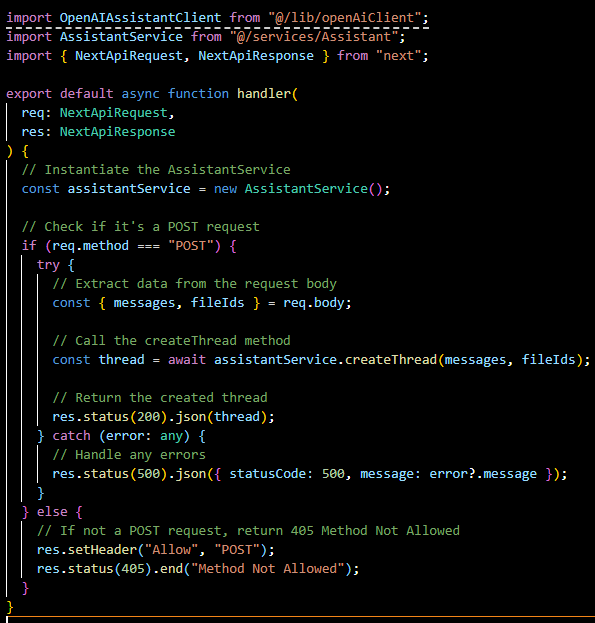
createThread.ts:
A POST endpoint to create a new thread. It takes messages and fileIds from the request body and uses the AssistantService to initialize a new conversation thread.
Each of these endpoints integrates with the AssistantService, which abstracts the interaction with the OpenAI API, making it possible to manage the lifecycle of assistants and their conversations effectively. This structure sets the foundation for the MTG Assistant's functionality, providing endpoints for creating assistants, managing conversations, processing natural language input, and handling user interactions.
The Assistant service, where the magic happens
The AssistantService class acts as a central hub for orchestrating the interactions between the OpenAI API, and the MTG SDK and provides all methods that we use in the endpoints. Let's walk through the core components and functionalities within this class:
Fields:
openAi: An instance of the OpenAIAssistantClient, which is the configured client used to interact with the OpenAI API.
actionsStore: A store for keeping track of actions required by the frontend. This is implemented as a dictionary where the keys are thread IDs and the values are actions to be taken.

Methods:
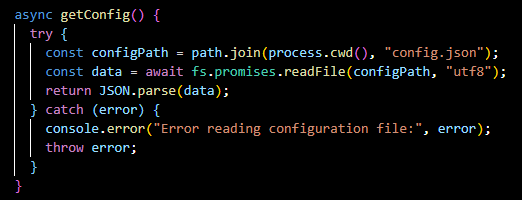
getConfig():
Retrieves the application configuration, likely from a config.json file, which includes necessary parameters for the assistant's operation.
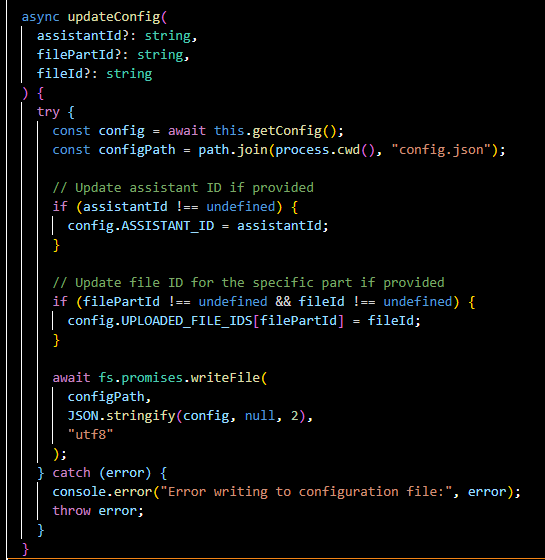
updateConfig(...):
Updates the configuration file, potentially with new assistant IDs or file IDs. This could be used to save the state of uploaded files or assistant references.
setFrontendAction(...):
Adds an action to the actionsStore, indicating that the frontend needs to perform some task.

getFrontendAction(...):
Retrieves an action from the actionsStore using a thread ID, which tells the frontend the next step to take.

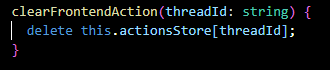
clearFrontendAction(...):
Removes an action from the actionsStore, indicating that the action is no longer required.
createAssistant(...):
Either fetches an existing assistant or creates a new one with specified parameters and tools, including uploading files if necessary.
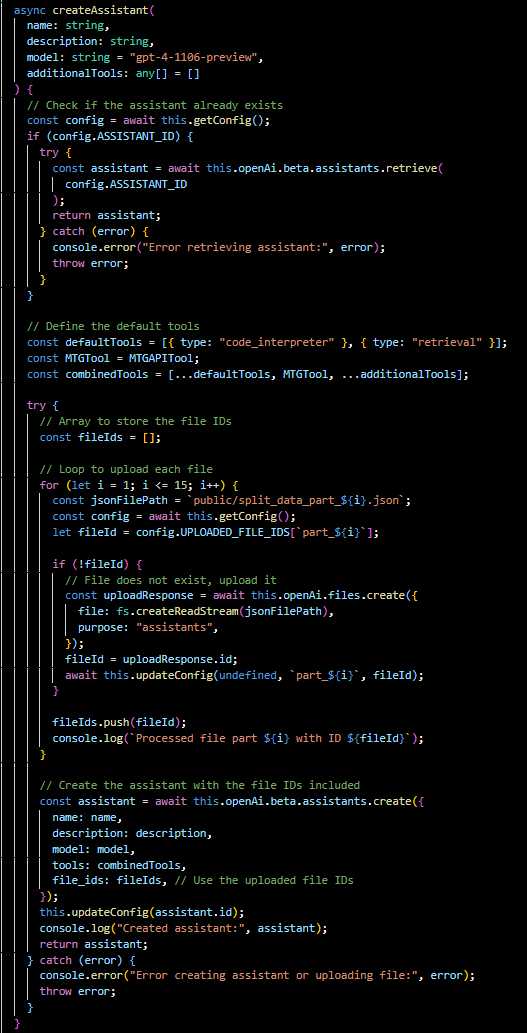
getAssistant(...):
Retrieves details about an existing assistant by its ID.
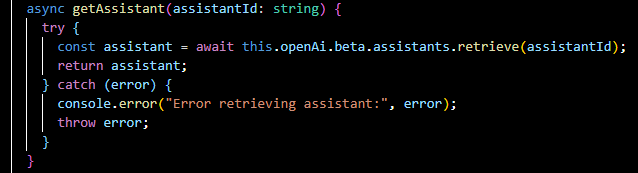
createThread(...):
Initializes a new conversation thread with messages and associated file IDs.
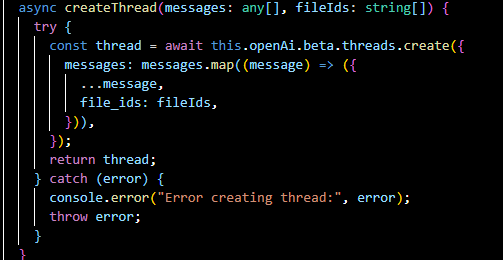
getThread(...):
Retrieves the details of a particular conversation thread.
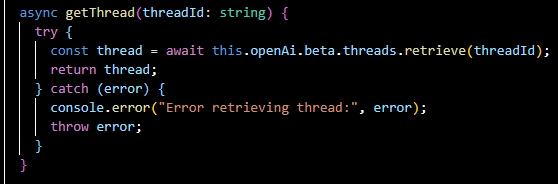
retrieveMessage(...):
Fetches a specific message from a thread by its ID.
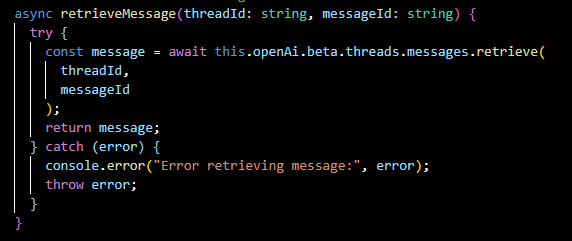
createRun(...):
Initiates a new 'run' within a thread, which is an execution instance where the assistant processes user input and generates a response.
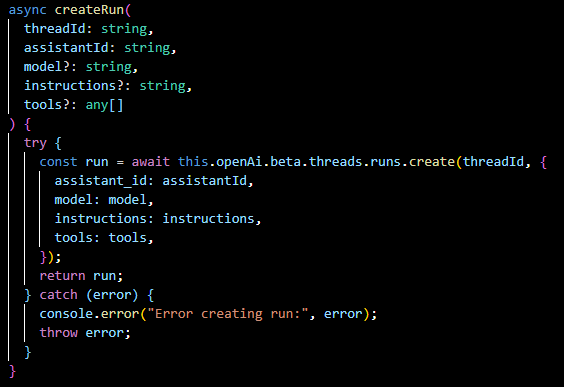
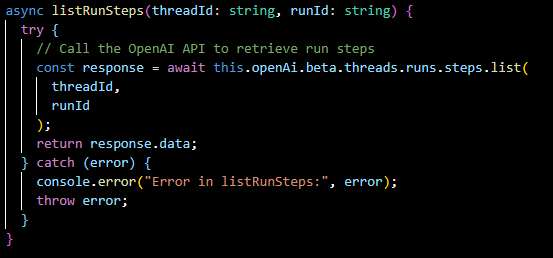
listRunSteps(...):
Retrieves the steps taken during a run, providing insight into the assistant's decision-making process.
addMessageToThread(...):
Adds a new message to a thread, either from the user or the assistant.

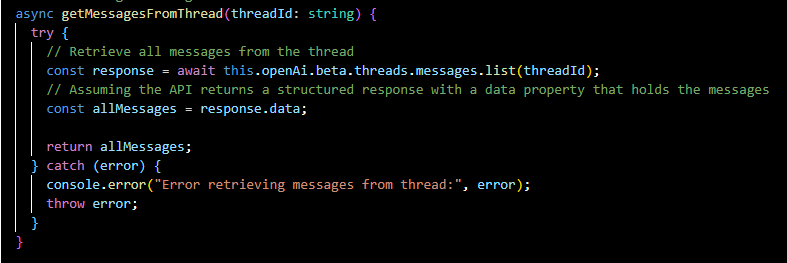
getMessagesFromThread(...):
Retrieves all messages from a specific thread.
getRun(...):
Fetches the details of a specific run within a thread.
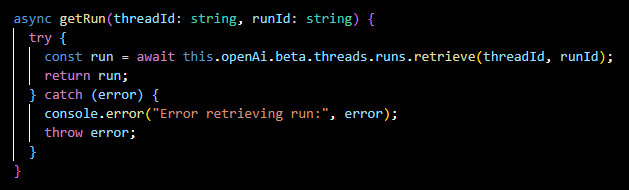
getRunStatus(...):
Retrieves the current status of a run, such as whether it's in progress, completed, or requires action.
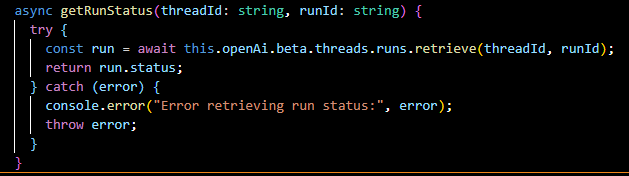
cancelRun(...):
Cancels an in-progress run.
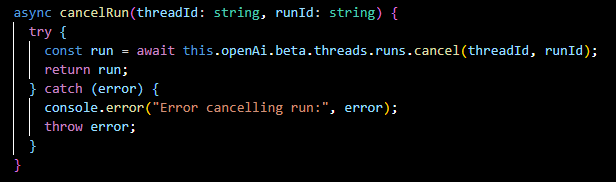
orchestrateRun(...):
The orchestrateRun method is a key part of the AssistantService class that manages the lifecycle of a run—a series of interactions or steps taken by the assistant in response to user input.
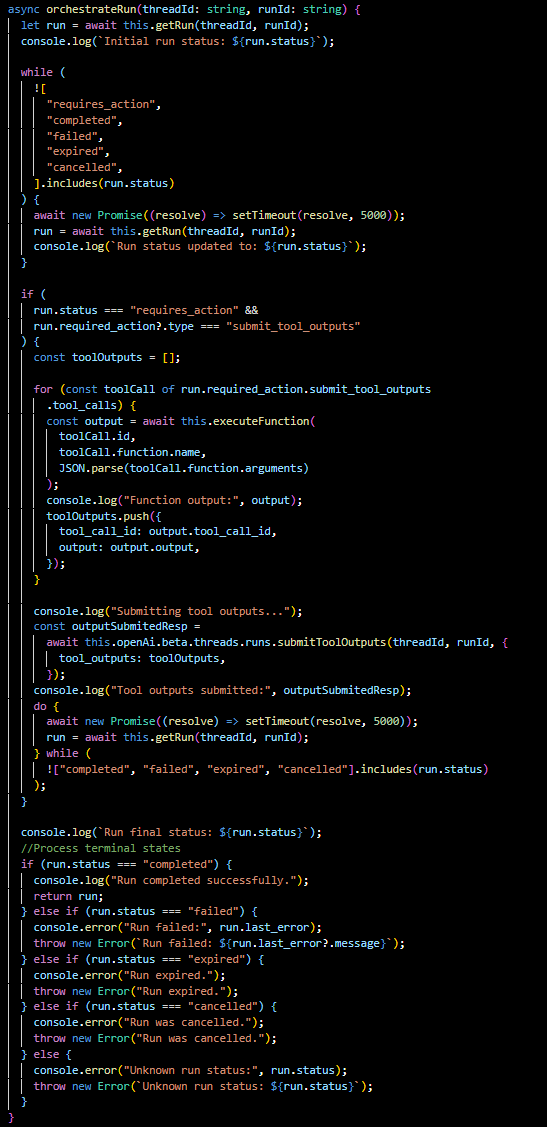
Let's dissect this method to understand its functionality and the significance of each part:
Run Initialization: The method begins by fetching the current status of the run using getRun. It logs the initial status, which indicates whether the run is queued, in progress, or requires some action.
Run Status Loop: It enters a loop that continues until the run reaches a terminal state (requires_action, completed, failed, expired, canceled). Inside the loop, it periodically (every 5 seconds, as shown) checks and logs the updated status of the run.
Action Requirement Handling: If the run's status is requires_action, the method looks for what action is needed. Specifically, if the assistant needs to submit outputs from a tool it called during the run, it iterates over each toolCall that was part of the required action.
For each tool call, the executeFunction method is invoked, which performs the actual logic required by the function (such as fetching data from the MTG API). The results are collected in toolOutputs.
Submitting Tool Outputs: Once all necessary tool outputs are gathered, the method submits them back to the OpenAI API using submitToolOutputs. This is critical because it allows the assistant to complete its processing with the new information obtained from the tools.
Final Run Status Check: The method then enters another loop to wait for the run to reach a final status, again polling every 5 seconds. Once a terminal status is confirmed, the method logs it.
Terminal State Handling: Depending on the final status, the method processes the outcome:
- If completed, the run finished successfully, and the results can be used or displayed to the user.
- If failed, expired, or cancelled, an error is thrown with an appropriate message. This allows for error handling upstream, such as retry logic or user notifications.
Frontend Function Determination: The isFrontendFunction helper method is a simple check to determine if a function call within the run is intended for frontend operations. This could be used to trigger UI updates or prompts to the user based on the assistant's processing.
In summary, orchestrateRun is an orchestrator for the assistant's operations, ensuring that each step of the run is executed, monitored, and concluded appropriately. By handling actions required by the assistant and submitting tool outputs, the assistant can perform complex tasks that may involve external data fetching and processing. This method encapsulates the logic needed to maintain a smooth and responsive interaction flow within the application, providing a bridge between the backend processing and frontend user experience.
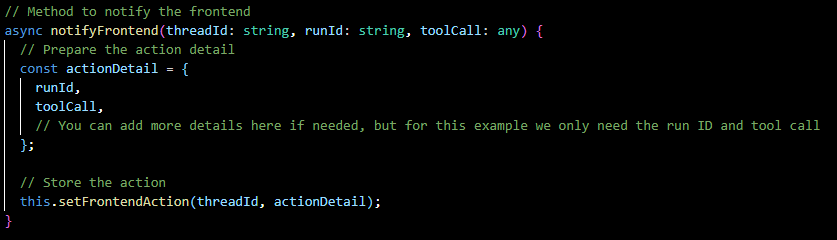
notifyFrontend(...):
Prepares and stores an action that the frontend should take, based on the state of a run.
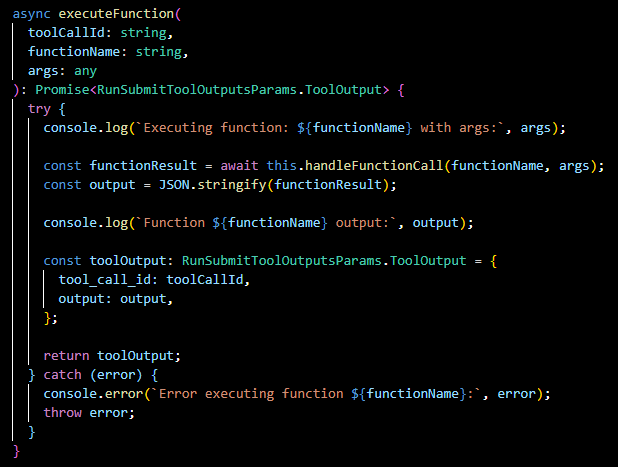
executeFunction(...):
Executes a specified function, part of the functionality provided by the OpenAI API to integrate the Assistants with arbitrary function calls that we define elsewhere.
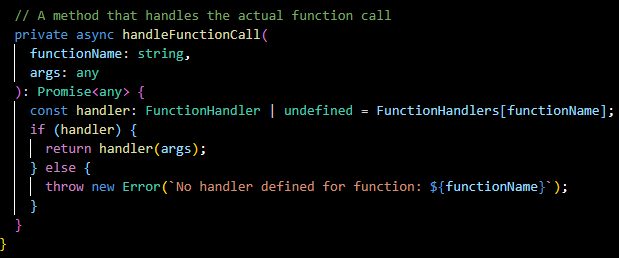
handleFunctionCall(...):
A private method that invokes the actual function handler based on the function's name, which is defined in the FunctionHandlers.
This class abstracts the complexities of managing the state and lifecycle of interactions with the OpenAI API, providing a clean interface for the rest of your application. It shows a thoughtful design pattern, separating concerns by breaking down the functionalities into discrete, purposeful methods, and managing configurations and actions in a centralized manner.
The class effectively bridges the gap between the MTG SDK's functionality and the OpenAI API, enabling seamless integration of these two powerful tools to create a responsive and intelligent MTG Assistant.
Tool file
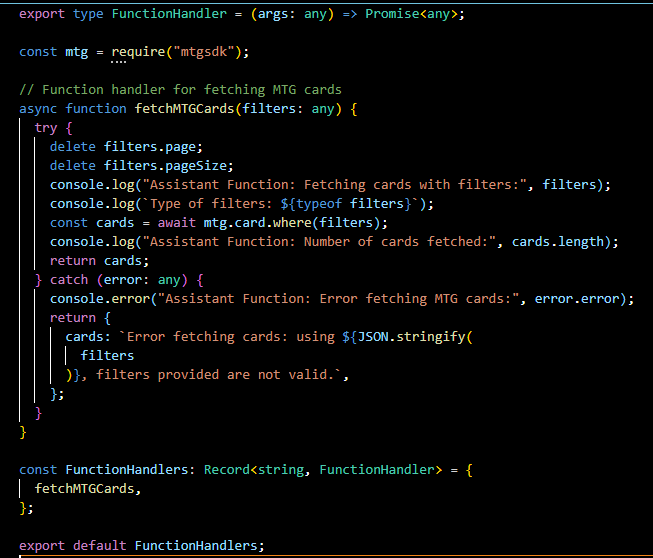
This file defines a set of function handlers that the Assistant API can use to perform specific tasks, in this case, fetching Magic: The Gathering (MTG) cards based on provided filters.
Let's go through the key components:
FunctionHandler Type:
The FunctionHandler type is a TypeScript type definition that ensures any function assigned to it will accept any type of argument and return a promise. This enforces a consistent interface for all function handlers, meaning they are all asynchronous functions that return a promise, which is typical for operations like API calls that are inherently asynchronous.
MTG SDK:
The mtg object imported from the "mtgsdk" package is the MTG SDK, a wrapper for the MTG API that simplifies fetching data about MTG cards. It abstracts the complexity of directly dealing with the API's HTTP requests and responses.
fetchMTGCards Function:
This is a specific function handler that utilizes the MTG SDK to fetch cards. It takes filters as an argument, which are the criteria for searching cards. Notably, it removes page and pageSize properties from the filters to prevent pagination issues, as this function aims to fetch all cards that match the filters, not just a subset.
Inside the function, it logs the action and filter types for debugging purposes. It then calls mtg.card.where with the filters, which returns a promise resolving to the array of cards that match the filters. Once the cards are fetched, it logs the count of cards retrieved.
If an error occurs, it is logged, and a descriptive error message is returned. This error handling is crucial for debugging and also for providing the user with feedback if the function can't complete as expected.
FunctionHandlers Object:
This is a JavaScript object that acts as a registry or directory of all available function handlers. By adding fetchMTGCards to this object, you are making it available to be called by the Assistant as needed. This pattern is very flexible and scalable, allowing new function handlers to be easily added and referenced by name.
Backend wrapup
In this section, we're wrapping up our backend exploration, highlighting the practical implementation of the OpenAI Assistant API. This backend exemplifies a working model—not flawless but functional—of what developers might construct leveraging the API's capabilities.
Endpoint Summary:
The endpoints, such as getAssistant and createAssistant, are straightforward gateways managing the assistants' lifecycle. They're designed to handle specific tasks like fetching assistant details and creating new instances upon request.
Check-for-action and the run management endpoints (cancelRun, steps, submitToolOutput) illustrate a basic yet effective system for monitoring and controlling the assistant's interaction flow. These endpoints aren't just static routes; they are part of a larger dialogue management system, capable of evolving with the user's needs.
AssistantService Insights:
The AssistantService class is the backbone of our backend, serving as an intermediary between the OpenAI API and our application's logic. With functions for configuration, action management, and run orchestration, it underscores a modular approach to building such systems. It's not about perfection but about creating a solid, maintainable foundation for the assistant's operations.
The orchestrateRun method, for instance, may not cover every edge case but provides a clear illustration of how to manage a run's progression, from initiation to completion, including error handling and status updates.
MTG SDK Functionality:
Integrating the MTG SDK through FunctionHandlers demonstrates how external data sources can be tapped into, expanding the assistant's utility. The fetchMTGCards function isn't an exhaustive search mechanism but serves as a sample of how one might retrieve and utilize external data within the assistant's framework.
Closing Reflection:
The backend we've discussed is a real-world example of what's possible with the OpenAI Assistant API. It showcases a journey from initial configuration to a fully interactive session, complete with dynamic data fetching and processing. It's a testament to the API's flexibility and a showcase of how it can be used to build an interactive tool, like our MTG Assistant, which, while not without room for improvement, is a step towards more sophisticated AI-driven applications.
Frontend
The frontend is pretty much a standard React application, meaning there is not much sense in showing exhaustively how it’s built. Instead, I’ll just highlight some key pieces.
Context:
This context is designed to handle and update the various states and actions of the assistant interaction.
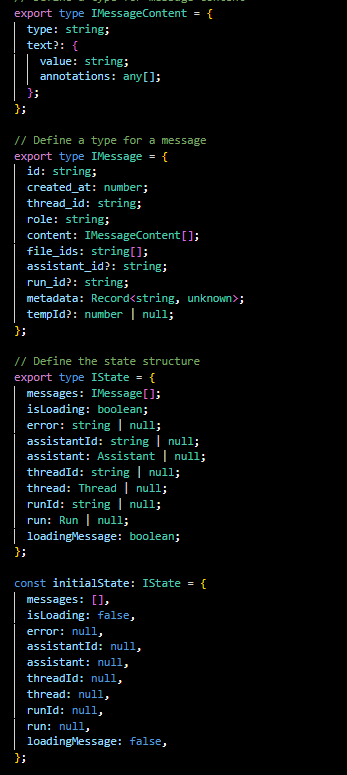
Here's a breakdown of its functionality and how it facilitates state management across the application:
State Definition: The context defines a state type (IState) which includes arrays for messages, status flags like isLoading, error messages, and identifiers and instances of various objects like assistantId, assistant, threadId, thread, runId, and run. This comprehensive state structure ensures that all relevant data about the assistant's interaction is maintained and accessible throughout the application.
Action Types: A series of action types are defined to specify the exact changes that can be dispatched to the context. Actions can add messages, set loading states, report errors, clear messages, and set specific identifiers and objects related to the assistant's operation.
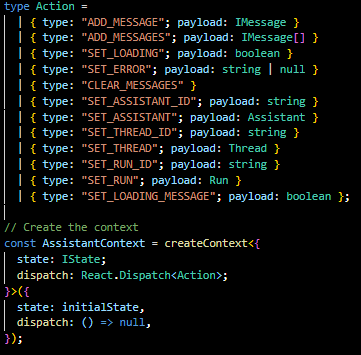
Reducer Function: The reducer function updates the state based on the action dispatched. It's a pure function that takes the previous state and action, and returns the next state. It's instrumental in maintaining predictability and control over state transitions.
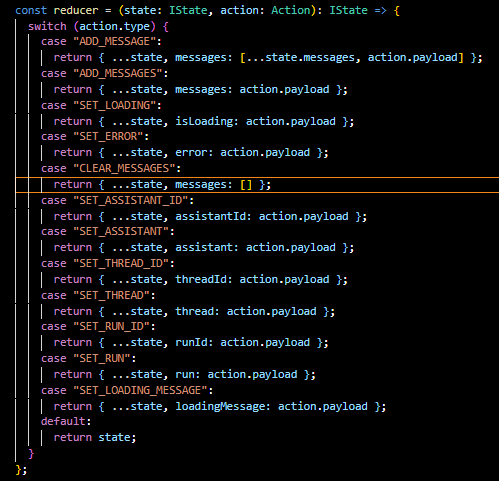
Context Provider Component: AssistantProvider is a component that wraps the application's components, providing them access to the context's state and dispatch function. This way, any component within the provider can interact with the assistant's state.
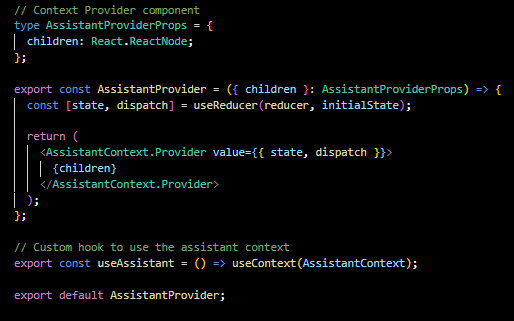
Custom Hook: The useAssistant hook is a custom hook that simplifies the consumption of the context in functional components, allowing for cleaner code and easier access to the assistant's state and dispatch function.
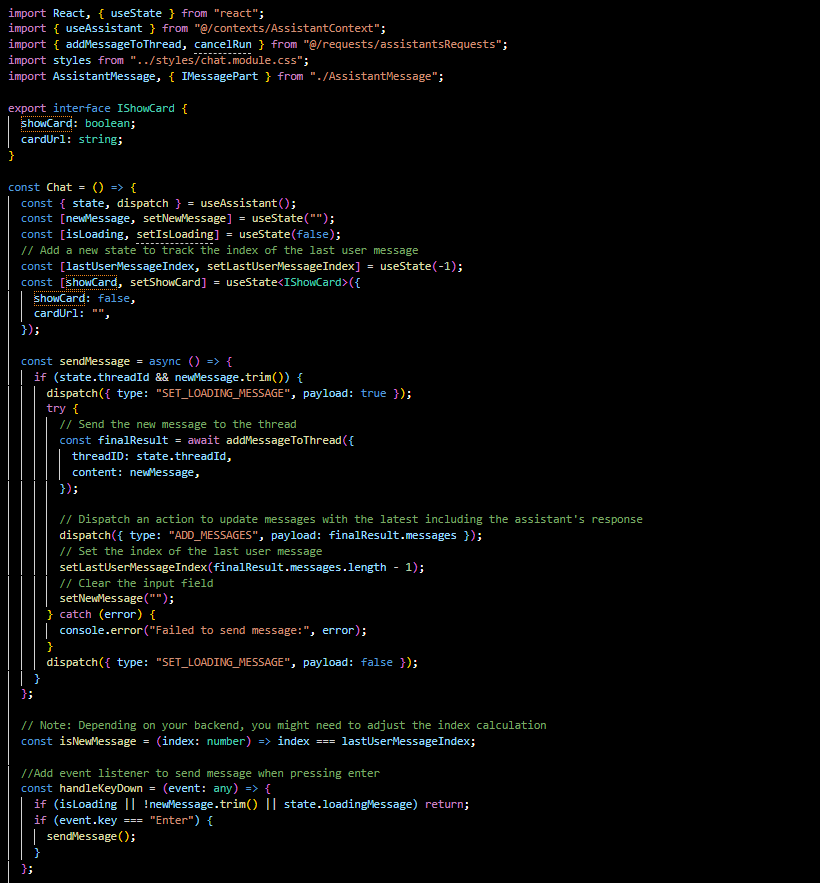
Chat.ts is the actual chat component:
The Chat component serves as the interactive core of our MTG Assistant's front end, where users can communicate with the assistant and receive responses.
Let's dive into the interesting facets of this component:
At its heart, Chat utilizes the useAssistant custom hook to access the assistant's state and dispatch functions from our earlier-defined context. This hook simplifies state management and helps keep our component clean and focused on the UI logic.
Key features of the Chat component include:
- State Management: We manage the state of the new message being typed by the user and a loading state to provide feedback during asynchronous operations.
- Message Handling: The sendMessage function is crucial. When invoked, it sends the user's message to the backend and updates the chat interface with new messages, both from the user and the assistant.
- UI Feedback: We've introduced isLoading and loadingMessage flags to manage UI indicators, like spinners, which signal to the user that the app is processing their input.
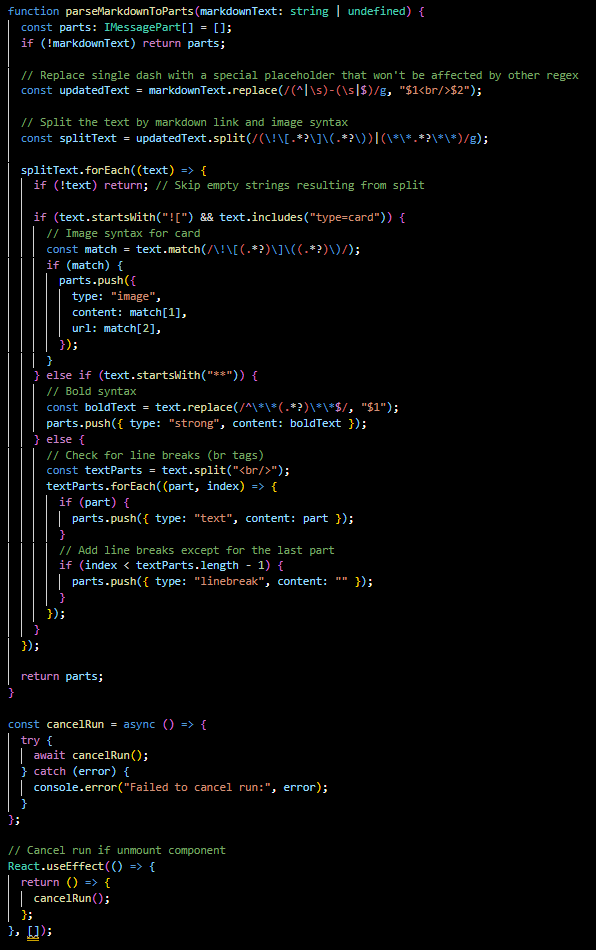
- Markdown Parsing: The parseMarkdownToParts function suggests that the app may receive messages formatted in markdown, which it then converts into displayable parts for the UI. The component also includes features to enhance the user experience.
- Keyboard Interactions: Users can send messages with the "Enter" key for quick interactions.
- Message Tracking: It tracks the index of the last user message to differentiate new messages from older ones in the chat flow.
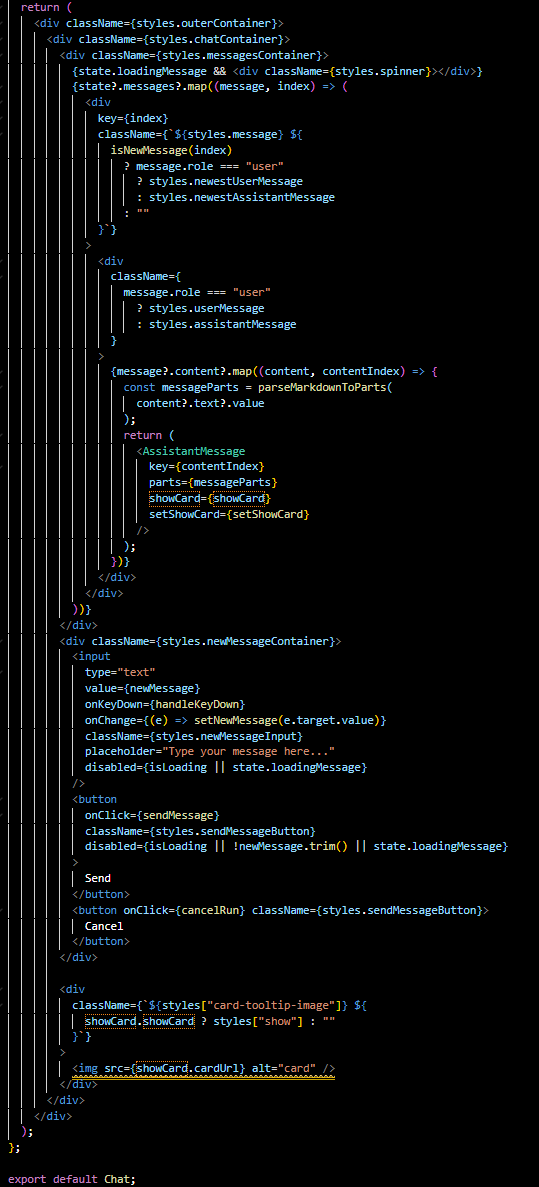
- Card Previews: The state showCard is used to show a preview of an MTG card, enriching the chat with visual content.
When a user types in their message and sends it, the component dispatches an action to update the state with this new message, reflecting the interactive chat in real-time. The messages are displayed in the UI, and any markdown formatting is interpreted to provide a rich chat experience.
Error handling is also a concern here, as indicated by the catch blocks in asynchronous functions, ensuring that any problems during message sending or run cancellation are caught and logged.
Finally, the component cleans up after itself using the useEffect hook, which triggers the cancelRun function when the component unmounts. This is an essential feature, preventing lingering processes on the backend if the user navigates away from the chat.
In summary, the Chat component encapsulates the user's interaction with the MTG Assistant, providing an interface for message input, handling the display of assistant responses, and ensuring a responsive and engaging user experience. It shows how React's powerful patterns and hooks can be leveraged to build an interactive chat interface that's both user-friendly and effective in connecting with the backend AI services.
Assistant’s files
The assistant has access to a set of files in JSON format with the entire MTG card database up to date and some text files with the game rules. These files were preprocessed, gathered beforehand, and uploaded to the Assistant using Open Ai’s API console. In total, it has 15 JSON files with all card data and a couple of text files with a summary of MTG rules and format rules.
Conclusion
As we wrap up this overview of the MTG Assistant project, it's clear that while this endeavor was ambitious and instructional, it remains very much a work in progress. This project is an example of exploring AI's potential in enhancing gaming experiences, specifically through the OpenAI Assistant API.
A Learning Experience: Building the MTG Assistant has been a journey filled with both challenges and discoveries. It's a reminder that in the world of technology and AI, there's always more to learn and room for improvement. The project's current state reflects an initial foray into the vast potential of AI-assisted applications.
Opportunities Ahead: Looking forward, the MTG Assistant has ample scope for development and refinement. From enhancing the AI's decision-making abilities to improving user interaction, each aspect of the project offers an opportunity for growth and learning.
Encouragement for Enthusiasts: For those intrigued by AI and its applications in gaming or other areas, this project serves as an encouragement to experiment and innovate. While perfection is not the initial goal, the process of building, testing, and iterating is where the real learning and progress happen.
In essence, the MTG Assistant project stands as a humble yet promising example of what can be achieved with dedication and a willingness to delve into the burgeoning world of AI. It's a call to embrace the learning process and see where your creativity and technical skills can take you in this exciting field.